Overview
This chapter explains the scope of this book and describes the basic architecture that an administrator can install, configure, monitor, and manage. Many of the issues that are covered in this book: monitoring, management, tuning, jobs, and scripting are relevant to more complex architectures; for this reason, this book remains the foundation of Perforce administration even if you are setting up more complex architectures.
It is strongly recommended that you read Introducing Helix before you read this book.
Basic architecture
The simplest Perforce (Helix versioning engine) configuration consists of a client application and server application communicating over a TCP/IP connection. The server application manages a single repository that consists of one or more depots. A client application communicates with the server to allow the user to view trees of versioned files and repository metadata (file history and other information). Clients also manage local workspaces that contain a subset of the files in the repository. Users can view, check out, and modify these local files and submit changes back to the repository. Archived user files are stored on the server either in local type depots or in stream type depots.
The following figure illustrates this basic architecture. Multiple users connect to the server and view files stored either in a streams type depot or a local type depot using workspaces (local directories) on their own machines.
Figure 1. Single Server
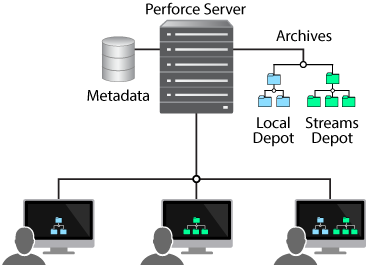 |
Administrators support this architecture by installing and configuring the server, setting up users and security, monitoring performance, managing the resources used by the server, and customizing the behavior of the server if needed.
Users can also work disconnected from the server: they use a personal server to manage their work locally and share their work with others via a shared server. This option expands the basic architecture, as shown in the next figure:
Figure 2. Shared servers
 |
Using this distributed versioning architecture, users can either connect directly to a shared server or work disconnected from the server, sharing their files with others by pushing or fetching content from their personal server to the shared server. Equally, an administrator can move content directly from one shared server to another by pushing and fetching content. Content can be moved across disparate networks, from one shared server to another shared server, by zipping and unzipping.
Administrators support this architecture by installing and configuring
the shared server, setting up users and security, monitoring
performance, managing the resources used by the server, and customizing
the behavior of the server if needed. Personal servers are automatically
set up when the user executes the p4 init or p4 clone
command to create (and populate) their workspace and depot.
The administrator can expand this basic architecture either to resolve issues of geographical distribution, or scaling, or both.
- Helix Versioning Engine Administrator Guide: Multi-site Deployment explores some of the ways this architecture can be expanded for geographic distribution and performance.
Basic workflow
This book is roughly organized according to the administrator workflow. This section summarizes the basic workflow for setting up, configuring, and managing the Perforce server.
-
Set up the environment in which you will install the Perforce server.
Review installation pre-requisites in Planning the installation.
-
Download and install the Perforce server.
-
Start the server.
See the appropriate section on starting the server in “Installing and Upgrading the Server”.
-
Execute the
p4 protectcommand to restrict access to the server. -
Configure the server.
Basic configuration includes enabling distributed versioning if needed, defining depots, defining case sensitivity and unicode, managing client requests, configuring logging,and configuring P4V settings. See “Configuring the Server”.
-
Define additional depots if needed.
-
Add users if they are not automatically added on login.
-
Secure the server: set up secure client-server connection. Set up authorization and authentication.
-
Back up the server.
-
Monitor server performance and resource use.
-
Manage the server and its resources: changelists, users, code sharing, disk space, and processes.
-
Tune the server to improve performance.
-
Customize Perforce by extending job definitions.
-
Customize Perforce using trigger scripts.
Administrative access
Perforce security depends on the security level that is set and on how
authentication and access privileges are configured; these are described
in “Securing the Server”. Access levels relevant for the administrator
are admin and super:
admingrants permission to run Perforce commands that affect metadata, but not server operation. A user with admin access can edit, delete, or add files, and can use thep4 obliteratecommand.supergrants permission to run all Perforce commands, allows the creation of depots and triggers, permits the definition of protections, and enables user management.
Users of type operator are allowed to run commands that affect server
operation, but not metadata.
All server commands documented in the P4 Command Reference indicate the access level needed to execute that command.
Until you define a Perforce superuser, every Perforce user is a Perforce superuser and can run any Perforce command on any file. After you start a new Perforce service, use the following command:
$ p4 protectas soon as possible to define a Perforce superuser.
Naming Perforce objects
As you work with Perforce, you will be creating a variety of objects: clients, depots, branches, jobs, labels, and so on. This section provides some guidelines you can use when naming these objects.
| Object | Name |
|---|---|
|
Branches |
A good idea to name them, perhaps using a convention to indicate the relationship of the branch to other branches or to your workflow. |
|
Client |
Depends on usage, but some common naming conventions include:
Whether you use A client may not have the same name as a depot. |
|
Depot |
Depot names are part of an organizations hierarchy for all your digital assets. Take care in choosing names and in planning the directory structure. It is best to keep the names short. A client may not have the same name as a depot. |
|
Jobs |
Use names that match whatever your external defect tracker issues look
like. For example |
|
Labels |
Site-dependent, varies with your code management and versioning needs.
For example: |
|
Machine Tags |
The host name, or something simple and descriptive. For example
|
|
User |
The OS user. |